
因為答應Marcel老師要去PyTorch Taichung報ResNet ,成立AI Seminar Taoyuan以及公司專案的需求,所以得好好研究如何使用深度學習這個技能.
經過之前蓋SVM[1]的摧殘後,看論文是相對簡單很多,不過在看LeNet-5[2]的論文原文時,還是一頭霧水:主要是關於核的初始化機制,這個感謝台灣人工智慧社團的各位大德不吝指教,才搞清楚每層核的數量和生成方式.
另一個是反向傳播(back propagation),因為以LeNet-5來說,要反向傳播的不只是純量(神經元間的傳遞權重,核權重和偏差權重),卷積核和池化核本身也是一個可以被訓練(反向傳播)的權重群集,不過光是之前要理解純量的反向傳播要幹嘛的時候,就花了不少時間在找資料.
找資料的狀況跟之前蓋SVM時雷同,大部分都是抄來抄去,點得很淺的文章,但能寫成程式碼的沒幾篇,後來找到Mark Chang的部落格[3]以及Marcel老師的部落格[4],加上重新手算一次後,才真的搞懂反向傳播在玩什麼,也才知道反向傳播還跟Loss function以及神經元的activate function有連動關係.
再來是想辦法把卷積核和池化核也反向傳播更新,這個也是想了老半天,後來也去網路上找了不少資訊,後來還是找到了些不錯的內容,也瞭解了卷積和池化核的反向傳播機制.
還有預訓練(pre-train)的數學方法,這個連網路資料都很少見,所以這個部分只能靠論文上給的公式慢慢參透,這樣斷斷續續從九月初搞到十一月底,幸好有大神寫過的[5]可以參考,雖然裡面的演算法沒有看懂(即使有把整個LENET實作出來,但他的寫法我還是看不太懂),不過在MNIST匯入和圖像處理這邊幫了很多忙~
以下是關於LENET5這篇論文的雜七雜八心得:
不免俗地還是講解一下架構:

總共六層
卷積層c1,有6個神經元,卷積核5*5大小,輸入為32*32的點陣圖,輸出為28*28的陣列,運算流程:
共有5*5(核權重)+1(偏差值)=26
6神經元=26*6=156個可訓練之參數
池化層s2(平均池化)
也是6個神經元,池化共用一個權重,跟上層的神經元為一對一關係,輸入為28*28陣列,輸出為14*14陣列
共有1(權重)+1(偏差)=2
6神經元=6*2=12可訓練參數
卷積層c3,有16個神經元,卷積核5*5大小,輸入為14*14的點陣圖,輸出為10*10的陣列,和s2為部分連接.可訓練的參數為
3*6+9*4+6=60(c3每顆神經元和s2神經元之間的連結數3為6顆,4個連結有9顆,6個連結為1顆,輸入傳遞也有個權重)如下表所示:

至於部分連結的目的是為了讓整個架構不對稱.
60*(5*5)+16(偏差權重)=1516個可訓練參數
池化層s4(平均池化)有16個神經元,輸入為10*10的陣列,輸出為5*5的陣列,和c3為一對一.可訓練的參數為:
共有1(權重)+1(偏差)=2
16神經元=16*2=32可訓練參數
卷積層c5,有120個神經元,卷積核5*5大小,輸入為5*5的陣列,輸出為1*1的陣列,和s4為全連接.可訓練的參數為:
16(輸入權重)*120*(5*5)(核權重)+120*1(偏差權重)=48120個可訓練參數.
非線性神經元層F6,有84個,為純量神經元,輸入和輸出皆為純量,和c5為全連接,可訓練的參數為:
120*84(輸入權重)+1*84(偏差權重)=10164個可訓練參數.
F6的84個結果,會直接對應到7*12大小的數字點陣圖,
比對的這一層我們就叫他輸出層吧,利用loss fuction來計算F6的結果和點陣圖的像素差異,並把誤差回傳給所有可變更的神經元權重們.
激勵函數:
在Lenet架構下的激勵函數和現在常用的函數(ReLU)不同:
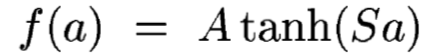
A=1.7159, S=2/3
會如此設計的原因,是因為作者想讓各層輸出的值儘量靠近在f(1)=1以及f(-1)=-1,這個也跟陣列資料的輸入處理有關係.
點陣資料輸入處理:
和現在常用的處理方式也不太相同,它是先把byte轉換,讓白(背景)的部分等於-0.1,黑(前景)的部分等於1.175,單張圖片的所有像素平均接近於0
權重初始化的範圍值:
在這邊作者是以-2.4/Fi~2.4/Fi當作初始化的範圍值,Fi是該顆神經元的輸入數目.假設上層有60顆神經元連結這顆神經元,則Fi=60.至於為什麼用2.4呢?好問題,我也還沒想到答案~
損失函數:
也就是所謂的Loss function,在LeNet使用所謂的L2,也就是平方差的總和.我發現這篇論文的作者很喜歡中途變換符號,所以很多時候不詳細看內文只看數學公式會突然抓不到他要表達的.
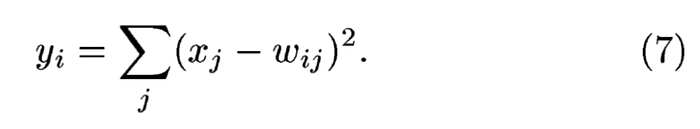
公式(7)的xj是F6層中84個輸出純量的其中一個,wij則是比對用的圖片的84個像素的其中一個,把每個輸出純量從j=1~84相加,就是yi.
至於公式(8),yDp則是第Dp個yi(公式7的yi),對於相對應的輸入Zp來說.損失函數E(W)其中的W是可訓練的權重的群集,假設這個數據集有500個,P=500
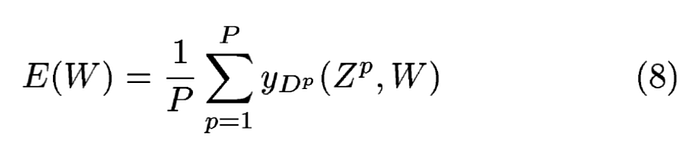
在LeNet中,還加上了懲罰項目,其數學公式如公式(9)
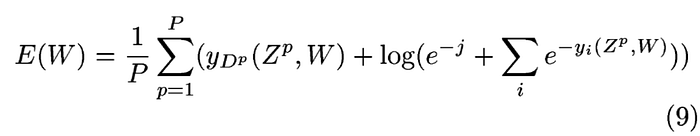
但我覺得效果還好,所以就沒在程式加上這一段.
反向傳播:
反向傳播算是神經網路最重要的一個手法了,主要是把誤差傳遞回所有的可訓練參數.公式如下,:
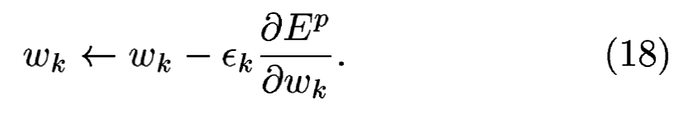
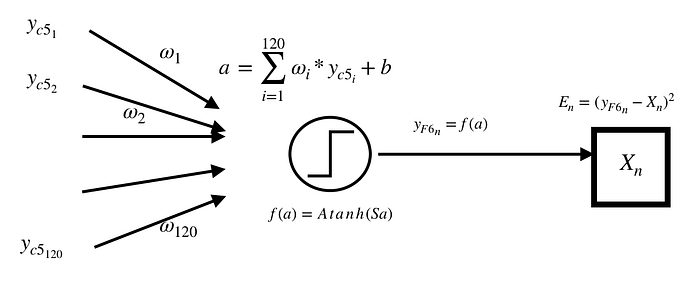
由於Mark大的部落格寫得非常清楚,所以我在這就只是簡述.以Loss function之Error 回傳到F6的一個神經元更新權重為例:
下圖是一顆F6神經元的示意圖,最後的Xn是相對應點陣的值,n從1~84,計算出損失函數的值.
假設我們今天要更新𝛚1,𝛚1= 𝛚1-𝛜(𝛛En/𝛚1),而(𝛛En/𝛚1)利用鏈鎖律,可以拆分成:
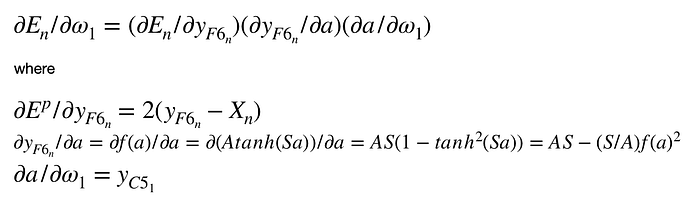
因此權重的更新就是把每一個步驟的微分過程串起來~最後乘上學習速率和權重本身相減,就是新的權重了.
預訓練:
這個的目的是為了在每一輪訓練正式開始前,先拿小批量(論文是500個)的樣本來調整學習速率,增進整體效能.這個搞了我好一陣子,主要還是數學符號不太習慣,但後來就突然看懂了,和反向傳播的方式很像,其公式如下:
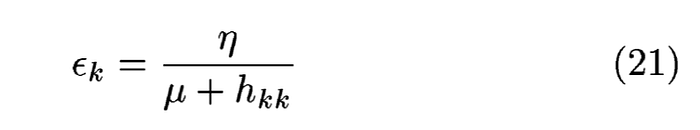
其中hkk,在論文裡寫道:hkk是權重𝜔k對損失函數的二次微分.𝛈和𝛍都是手動設定的常數.用來避免hkk=0或太大的時候會整個炸掉的狀況.在論文中,所使用的最佳化手法是用Levenberg-Marquardt method.這個要詳細講的話得再出一篇才行(也許會和最佳化手法一起講解)~所以先留著.但是運算過程可以粗略地講解~
首先:求出Loss function對輸出結果的二次微分:
由於權重𝜔k不一定是單一一個,很多時候一整個群集,因此二次微分的公式會寫成(22),其中uij,ukl都是𝜔k的群集內的元素.對於這種多變量實值函數的二次偏導數可以參考海森矩陣[6]
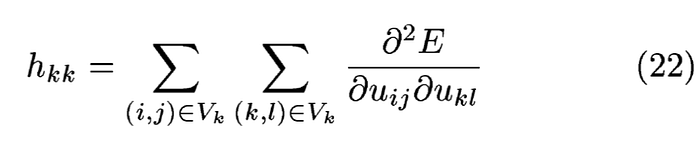
由於當時的電腦不是很好,所以為了節省運算量,因此作者只留下海森矩陣中對角部分的元素.如(23)

由於前面有提到損失函數的內容(公式(8)),因此把E展開後,就會變成(24)

根據鏈鎖率,我們拿剛剛權重更新中的F6層的一神經元中的𝛚1來當例子:
一次微分如下:
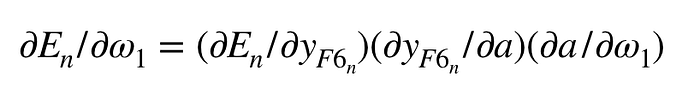
二次微分則是:
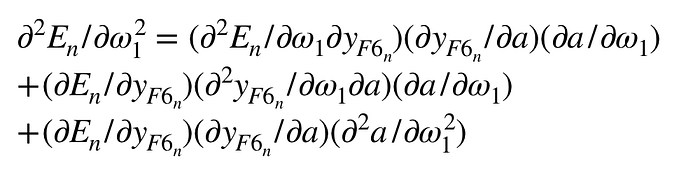
其中:
第一項的二次微分式可拆成:
先計算其中二次微分的分項
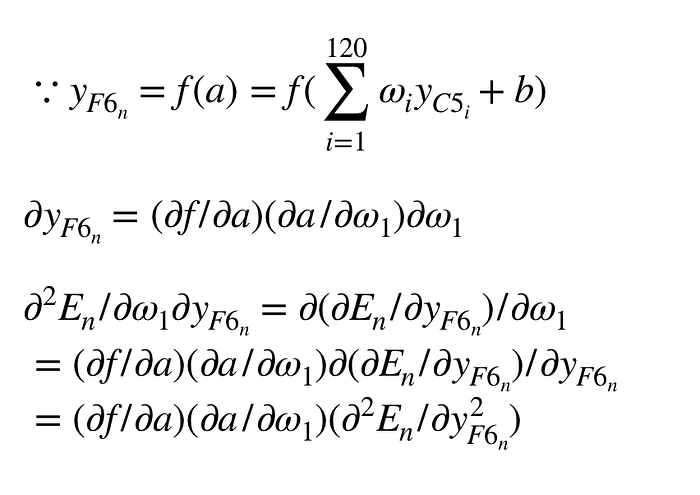
上面的運算結果合併回第一項可得:

第二項的二次微分式:
先計算其中二次微分的分項:
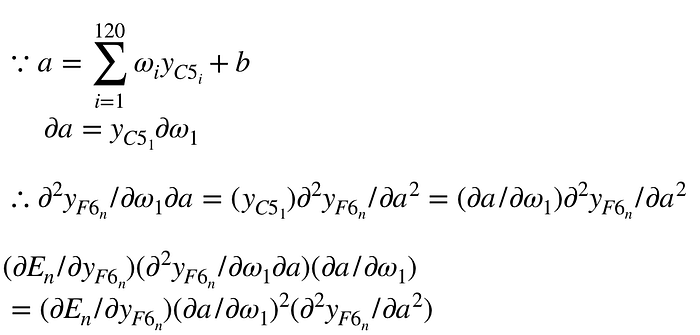
第三項的二次微分式:
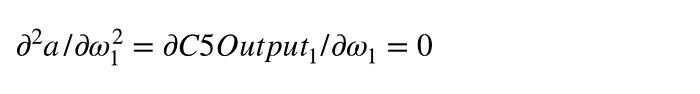
根據上面三個分項的二次微分式子,帶回主要的二次微分式子:
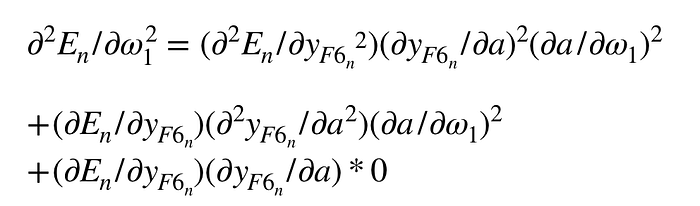
把
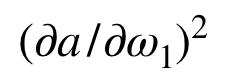
這一項提出來,原本的二次微分式就可改寫成:
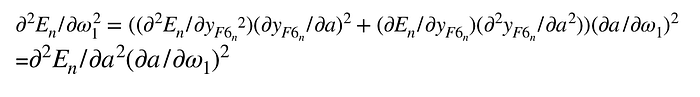
寫到這邊,就可和LeNet中的公式(25)和(26)互相比對了,
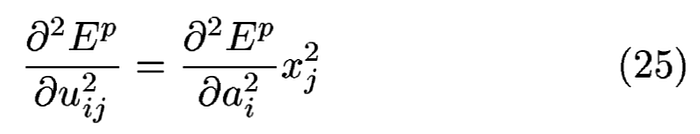
可以類比的地方:
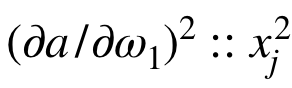
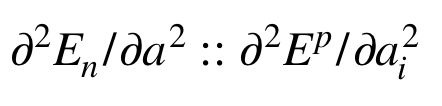
二次微分的算是可以歸納成(26)
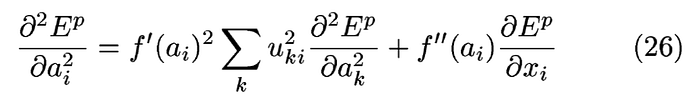
用這篇文的符號來寫則是:

作者在這邊認為激勵函數的二次微分項可以忽略不計,因此式子可以改寫成(27)
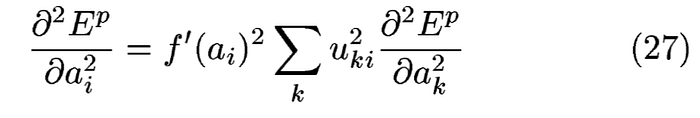
用這篇文的符號來寫則是:
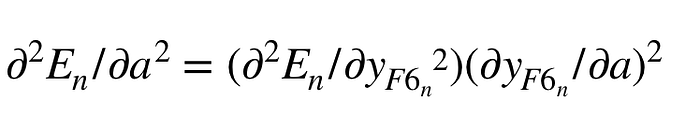
以上即hkk的簡略推導,由於在純量核中的權重都是一對一,因此Sumation只有一項,所以可以省略不寫,但在摺積核和池化核的時候,每個權重會和很多個輸入產生交互作用,在這個情況下就得把交互的所有狀況都加起來.
參考:
[2]http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
[3]http://cpmarkchang.logdown.com/posts/277349-neural-network-backward-propagation
[4]http://hemingwang.blogspot.com/2017/04/lenet.html
[5]https://github.com/patrickmeiring/LeNet
[6]https://zh.wikipedia.org/wiki/%E6%B5%B7%E6%A3%AE%E7%9F%A9%E9%98%B5